この記事では、EDINETのデータを収集するために
BeautifulSoupを使ってスクレイピングしたのでそのことを残しておきます。
コードも載せます。
はじめに
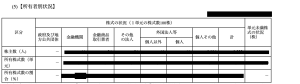
今回の目的は上の画像のようなEDINET上で公開されているデータの表の情報をスクレイピングで取得して、取得したデータをデータベースに保存するといったもの。
これに近い作業を行う人向けの記事になるかと思います。
先に結論を言っておくと今回実装したコードでは、も約1割の会社の目的の情報が取得出来ませんでした。
実装
実装はここに公開しています。
READMEに従えば、実行できると思うので説明は割愛。
GitHub - shiki0428/scraping
Contribute to shiki0428/scraping development by creating an account on GitHub.
github.com
プログラムは脳死で書いているので変数名などにケチつけないでください。
ファイルそれぞれの役割は大体以下のようになっています。
- create_db.py =>sqlite テーブル作成
- docid_download_from_edinet.py =>edinetからzipダウンロード
- zip2xbrl.py =>zipを解凍
- shareholderComposition.py =>【所有者別状況】の表の情報をDBに登録
- shareholderComposition_2.py =>【所有者別状況】の表の情報をDBに登録 取得できなかったできなかった約100社を追加取得
結論
今回実装したコードでは、約1割の会社の情報が取得出来ませんでした。
原因としては、edinetに公開しているファイルのうちformatに従っていない会社があるので、これらの会社の情報はうまく取得出来ませんでした。
仮に1年分の情報を取得するとなると約4300社ほどあり、そのうち約4000社の情報は自動で取得できているので全手動よりは確実に楽はできていると思いますけど。。。
実装している側としてもモヤモヤする結果になりました。
EDINET側でももう少しformatを厳しくしていただけるとありがたいですね。


コメント